慢查,顾名思义就是很慢的查询。
SQL的执行总是有一个执行时间的,通过long_query_time参数可以告诉MySQL,当SQL的执行时间超过该参数的指定值后就将这条SQL记录在慢查日志中。
默认的long_query_time默认值为10s。

默认的慢查时长为10s,肯定是需要调整的。
例:设置全局慢查时间为0.2秒。

注意:long_query_time属于dynamic类型的参数。
意思是像上面这样在会话A中通过命令行的方式设置全局 long_query_time为0.2秒后,再打开一个新的会话B查看该变量会发现 long_query_time=0.2
但是在会话A中查看session级别的long_query_time依然为默认的10s
在MySQL5.1之前确实慢查日志确实是以文件的形式存在。
但是MySQL5.1之后MySQL允许我们可以将慢查日志放入一个数据表中,便于我们查看分析。

现在公司使用的一般都是5.6~5.7版本。当然即使5.1版本之后支持了将数据放入Table中,默认配置依然是File。
当然你也可以通过下面的命令将慢查输出类型改成Table

研发同学都知道:对于Linux操作系统来说,一个进程能打开的Socket文件句柄是上限的。即使我们可以动态的调整它的大小,但是也做不到无限大。
通过命令: 查看进程被限制的使用各种资源的量。
ulimit -a
core file size: 进程崩溃是转储文件大小限制
man loaded memort 最大锁定内存大小
open file 能打开的文件句柄数
大量的慢查占据MySQL连接(Linux操作系统会为每一条连接创建socket文件),慢查累积到一定程度还会导致正常的SQL得不到连接执行从而变成慢查SQL。
最终有可能导致MySQL的连接全部被耗光而夯死。这就是生产级别的事故了。
5.1、查看曾经执行完成的慢查
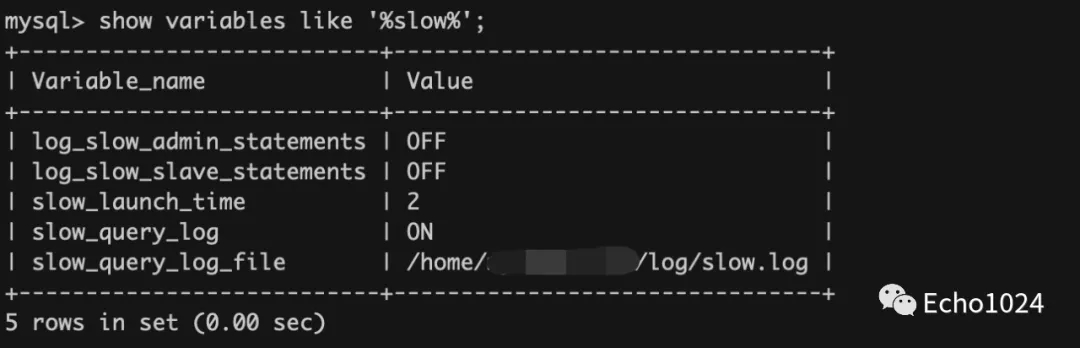
如果你需要编写一个监控程序探测MySQL的慢查询。那完全可以探测分析MySQL的slow.log
如果你还不知道slow.log在哪里,可以像下面这样定位到它。slow.log中记录的就是曾经执行过的慢查信息。
这时你可以尝试使用select sleep(2);模拟一条慢查SQL
然后去慢查sql中查看具体的慢查详情。

5.2、查看正在进行的慢查SQL
我在A Session中发起SQL:select sleep(60);
然后在B Session中通过下图的方式可以看到当前正在进行的慢查情况。大家在看的时候注意:Command的类型为Query

MySQL也为用户提供了一些原生的慢查工具。比如:查看执行时间最长的10条SQL。
mysqldumpslow -s a1 -n 10 mysql.slow_log
了解即可~
首先你得知道通常情况下每个公司都有自己监控系统,或者是监控脚本,具体的监控逻辑就是上节讲述的思路。故一旦出现报警,DBA同学会在第一时间接到消息。
DBA同学一般都会去联系业务同学,由业务同学去处理这个慢查。(相信已经工作的同学深有这个体会)
有可能爆出慢查的这套数据库集群是由多个业务同时使用。所以如果慢查影响很严重,DBA同学会询问业务同学是否可以kill 慢查。坚决不能让MySQL夯死!但是kill的方式其实是治标不治本!而且只要kill,就难免会误伤用户的SQL。
你可以像下面这样kill一个SQL
还是这张图:我们可以看到select sleep(60);已经执行了56秒了。

于是可以使用 kill 12 来断开它占用的连接。
但是kill的方式其实是治标不治本,很可能你刚给它断连,它马上又建立连接了。而且只要kill,就难免会误伤用户的SQL。
接下来就需要研发同学通过explain分析SQL
情况1: 通过explain你可能会发现,SQL压根没走任何索引,而且现在表中的数据量巨大无比。
这时就得根据select的内容创建合适索引。
情况2: 也可能是数据量太大了,即使走了索引依然超过了阈值。
这种情况其实挺糟糕的,DBA同学能做的依然只能是kill这些出事的SQL。最好的解决方案其实是分表,比如将大表拆分成128张小表。如何来不急做分表,可能这条SQL面临被下线的风险。
此外:通过explain查看SQL执行计划中的key字段。如果发现优化器选择的Key和你预期的Key不一样。那显然是优化器选错了索引。
那最快的解决方案就是:force index ,强制指定索引。
当你发现即使你使用了force index之后,查询依然很慢。这就意味着,你得设计一个更好的索引。
基数:上一篇文章中白日梦有跟大家分享。cardinality的统计是一个估算的结果,而且它也并不会实时的更新。所以这就可能出现一开始由于数据量小且没有代表性。导致基数很低。导致优化器选错了索引。针对这种情况,可以通过analyze table t 重新计算统计信息。
扫描行数、排序:更少的扫描行数意味着可能需要更少的磁盘IO,所以MySQL选择扫描行数少的key的可能性就更大。扫描行数并不是优化器选择索引的唯一依据,很可能出现你期望SQL走一个二级索引keyX,但是优化器偏偏走了主键索引。这是因为优化器考虑到了你select a,b,c,d from xxx;可能还有回表,IO代价也很高。
如果你有order by语句需要mysql帮你做排序,那MySQL就更倾向选一个查询出来的数据本来就有序的索引。
注意:本文归作者所有,未经作者允许,不得转载
